Gli aggiornamenti architetturali in Haswell
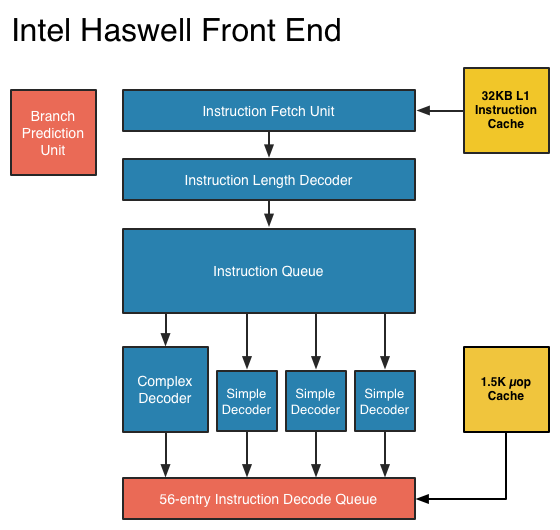
Andiamo ora a scoprire i piccoli cambiamenti che quest’anno Intel ha apportato per garantire quel costante miglioramento di IPC, immancabile per una nuova architettura. Ricordiamo a grandi linee che gli step principali all’interno della CPU per l’esecuzione di un’istruzione sono il fetching ed il decoding dell’istruzione (front end), e l’esecuzione e il salvataggio in memoria del risultato (back end). La pipeline di Haswell, come quella di Sandy Bridge è composta di 19 step, che scendono a 14 nel caso in cui l’istruzione da eseguire si trovi nella cache delle microoperazioni già decodificate (cosa che accade nella maggior parte dei casi). A titolo comparativo le ultime CPU con architettura Netburst ne avevano ben 31!
(Immagine a cura di Anandtech)
Nel frontend i miglioramenti sono limitati all’unità di Branch Prediction, ovvero quella che tenta di indovinare se delle istruzioni condizionali verranno eseguite o meno, adeguando di conseguenza il comportamento del frontend, ed alla coda delle istruzioni decodificate, che è stata unificata su tutte le 56 porte.
(Immagine a cura di Anandtech)
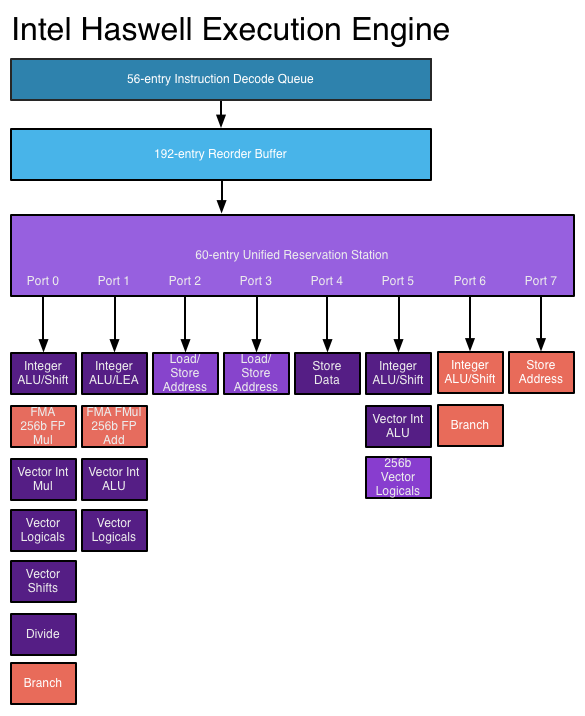
Nel backend, invece, dove le micro-operazioni decodificate vengono eseguite, troviamo le novità più interessanti. Una delle peculiarità più interessanti del core di una CPU è quella di poter eseguire più istruzioni in parallelo, dopo esser state accuratamente riordinate. Sin dall’introduzione del Conroe, Intel ha adottato un’architettura a 6 porte, ovvero potevano essere eseguite contemporaneamente fino a 6 operazioni. Con Haswell sono state introdotte due porte addizionali, una dedicata alla memorizzazione degli indirizzi, e un’altra dedicata ad una unità di calcolo per interi aggiuntiva.
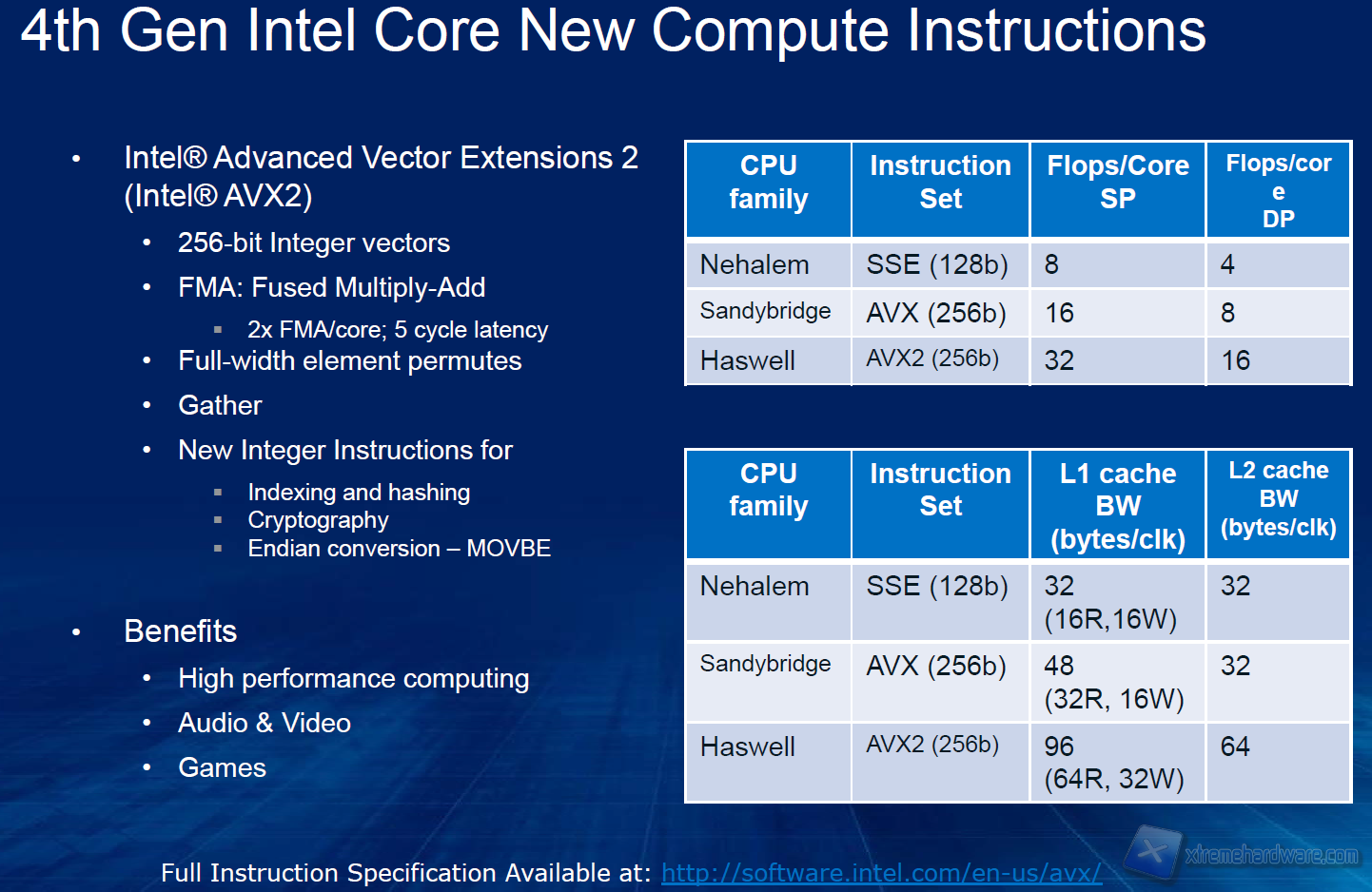
Sono inoltre state introdotte 2 unità FMA in grado di supportare quindi le istruzioni Fused Multiply-Add, in grado di velocizzare in modo determinante le applicazioni multimediali e di rendering 3D che le supportano. Tali operazioni erano state già introdotte da AMD con l’architettura Bulldozer. Le istruzioni FMA fanno parte del nuovo set di istruzioni Intel Advanced Vector Extension 2 (AVX2) che permettono un raddoppio del throughput massimo in single e double precision. Rispetto a Sandy bridge, è stata inoltre raddoppiata la bandwidth della memoria L1 sia per le operazioni di Load e Store sia come interfaccia con la L2.
Per far fronte alla maggior necessità di parallelismo nelle esecuzione delle istruzioni, Intel ha incrementato le dimensioni della maggior parte dei buffer che coinvolti nell’esecuzione delle istruzioni, a partire dall’importante finestra di esecuzione Out-of-Order.